根据2018年09月16日武汉·光谷猫友会,武汉的Gopher小伙伴分享的Go并发编程整理的内容。本次分享的主题内容包含Go语言并发哲学,并发的演化历史,你好并发,并发的内存模型,常见的并发模式等内容。关于并发编程的补充内容可以参考《Go语言高级编程》第一章的相关内容。
本次整理并发的内存模型部分的内容。
原子操作
在早期,CPU都是以单核的形式顺序执行机器指令。在单核CPU时代只有一个核在读或写数据,因此数据读写不需要额外的保护。但是进入多核时代之后,同一个数据可能被运行在不同CPU上的多个线程同时读写,因此需要额外的手段保证数据的完整性。原子操作则可以保证数据在被原子读或写的操作时不会被其它线程打断,因此可以保证读写数据状态的完整性。
Go语言的sync/atomic包提供了对原子操作的支持。sync/atomic包主要针对四字节或八字节大小并且地址对齐的内存进行原子读写,可以用于整型数或指针等基础数据类型。还有针对更复杂的atomic.Value类型,可以用于存储结构体对象。
在Go语言中,其实不使用sync/atomic包也可以编程。但是sync/atomic包在某些底层的代码中,可以为性能优化提供更多的灵活性。比如标准库中的sync.Once对象的Do函数:
type Once struct {
m Mutex
done uint32
}
func (o *Once) Do(f func()) {
if atomic.LoadUint32(&o.done) == 1 {
return
}
// Slow-path.
o.m.Lock()
defer o.m.Unlock()
if o.done == 0 {
defer atomic.StoreUint32(&o.done, 1)
f()
}
}
其中atomic.LoadUint32(&o.done)在开始先以极小的运算代价(院子操作是sync.Mutex等高级元语的代价更低)判断Once对象是否已经运行过了,如果没有则通过sync.Muyex.Lock进行加锁后在运行once对象。如果是第一次运行,则在退出前通过defer atomic.StoreUint32(&o.done, 1)设置已经运行过的状态标志。
基于原子包提供的函数可以构造更高级的sync.Mutex等并发编程的工具。不过Go语言的并发哲学是:不要通过共享内存来通信,而是通过通信来共享内存!因此我们需要尽量避免直接使用sync/atomic包提供的原子操作来进行并发编程。
同一个Goroutine内: 满足顺序一致性内存模型
所谓的内存一致性内存模型就是代码的书写的顺序和执行的顺序是否是一致的。对于单线程的程序来说,代码一般是以书写的顺序执行的。更准确地说,顺序一致性内存模型一般是针对代码块中的语句。
比如以下的代码就是满足顺序一致性内存模型的:
var msg string
var done bool = false
func main() {
msg = "hello, world"
done = true
for {
if done {
println(msg)
break
}
println("retry...")
}
}
其中先初始化msg字符串变量,然后将done设置为true表示字符串初始化工作已经完成。因此我们可以通过判断done的状态来间接地推导msg字符串是否已经完成初始化。在Go语言中,同一个Goroutine内满足顺序一致性内存模型。因此上述代码可以正确工作。
不同Goroutine之间: 不满足顺序一致性!
如果我们将初始化msg和done的代码放到另一个Goroutine中,情况就完成不一样了!下面的并发代码将是错误的:
var msg string
var done bool = false
func main() {
go func() {
msg = "hello, world"
done = true
}()
for {
if done {
println(msg); break
}
println("retry...")
}
}
运行时,大概有几种错误类型:一是main函数无法看到被修改后的done,因此main的for循环无法正常结束;二是main函数虽然看到了done被修改为true,但是msg依然没有初始化,这将导致错误的输出。
出现上述错误的原因是因为,Go语言的内存模型明确说明不同Goroutine之间不满足顺序一致性!同时编译器为了优化代码,进行初始化的Goroutine可能调整msg和done的执行顺序。main函数并不能从done状态的变化推导msg的初始化状态。
通过Channel对齐时间参考系
每个Goroutine类似一个个独立的宇宙,有着自己的时间系统。当一个Goroutine中的某些操作不可被观察的时候,那么他们的执行状态和执行顺序是未知的。只有当一个Goroutine的某些事件被另一个Goroutine观察的时候,这些事件的状态才会变得确定。观察的手段有很多,通过Channel对齐不同Goroutine的时间参考系是常用的方式。
下面的代码中,通过将done改为管道类型修复前面的错误:
var msg string
var done = make(chan struct{})
func main() {
go func() {
msg = "hello, world"
done <- struct{}{}
}()
<-done
println(msg)
}
done管道的发送和接收会强制进行一次同步main函数的主Gorotuine和后台进行初始化工作的Goroutine。在main函数执行<-done语句完成时,那么后台Goroutine比如也已经执行到了done <- struct{}{}语句,此时后台Goroutine的msg初始化工作必然已经完成了。因为后台Goroutine的msg初始化工作被main函数通过done管道观察了,因此编译器必须要保证msg在这个时刻完成初始化。因此最后main函数可以正常打印msg字符串。
通过sync.Mutex对齐时间参考系
对齐时间参考系的方式很多,除了通过管道来同步,还可以通过sync包的Mutex来实现同步:
var msg string
var done sync.Mutex
func main() {
done.Lock()
go func() {
msg = "hello, world"
done.Unlock()
}()
done.Lock()
println(msg)
}
代码中,sync.Mutex必须先Lock然后再Unlock,因为直接Unlock一个Mutex对象会导致panic。代码中,done.Unlock()和第二个done.Lock()分别在不同的Goroutine,它们会强制做一次时间同步。因此最后main函数也可以正常打印msg字符串。
带缓存的管道
管道是Go语言内置的并发原语。在刚学习Go语言,一般使用的是没有缓存的管道,它是缓存长度为0的管道。对于带缓冲的Channel,对于Channel的第K个接收完成操作发生在第K+C个发送操作完成之前,其中C是Channel的缓存大小。 如果将C设置为0自然就对应无缓存的Channel,也即使第K个接收完成在第K个发送完成之前。因为无缓存的Channel只能同步发1个,也就简化为前面无缓存Channel的规则:对于从无缓冲Channel进行的接收,发生在对该Channel进行的发送完成之前。
基于带缓存的管道可以实现对并发数量的控制:
func main() {
var wg sync.WaitGroup
var limit = make(chan struct{}, 3)
for i := 0; i < 10; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
limit <- struct{}{} // len(limit) 小于 cap(limit) 才能进入
defer func(){ <-limit }() // 退出时 len(limit) 减 1
println(id)
}(i)
}
wg.Wait()
}
因为limit管道的长度为3个,因此for循环内部创建的Goroutine在执行println语句时,在同一个时刻最多只能有3个Goroutine在并发执行。
初始化顺序
Go语言中每个包被导入时都会执行包的初始化操作,包括全局包变量的初始化和init初始化函数的执行。如果在包的初始化解决启动了新的Goroutine,那么这些新启动的Goroutine将不能马上被执行,它们只有在所有的包初始化都完成之后才能被创建。在初始化阶段创建的新Goroutine将和main函数是并发执行状态。
包的初始化示意图如下:
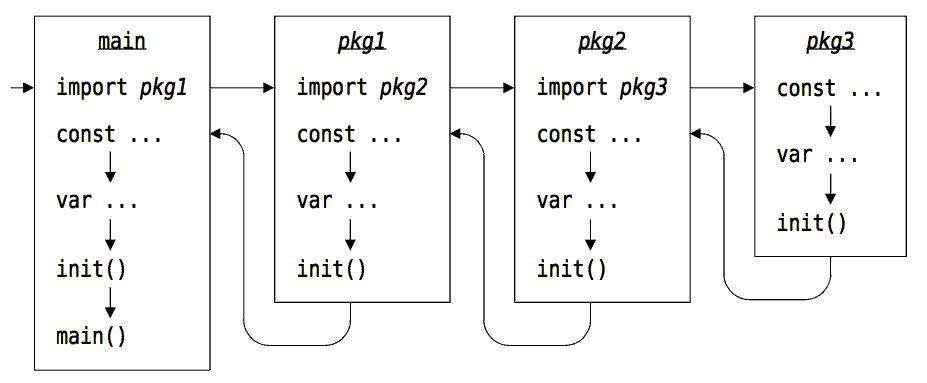
初始化是由runtime.main启动,伪代码如下:
func runtime.main() {
for pkg := range impported_pkg_list {
pkg.init()
}
go goroutines_from_init()
main()
}
首先顺序执行导入包的初始化工作,然后并发启动包初始化阶段启动的新Goroutine,同时并发启动main函数。
Goroutine特点
Goroutine是每个并发执行代码的容器,和传统操作系统中线程和进程有点类似。但是Go语言的Goroutine也有自己的特点,理解这些特色是写好并发程序的前提。
Goroutine特点:
- 由go关键字启动, 是一种轻量级的线程
- 以一个很小的栈启动(可能是2KB/4KB), 可以启动很多
- Goroutine栈的大小会根据需要动态地伸缩, 不用担心栈溢出
- m个goroutine运行在n个操作系统线程上, n默认对应CPU核数
- runtime.GOMAXPROCS用于控制当前运行运行正常非阻塞Goroutine的系统线程数目
- 发生在用户态, 切换的代价要比系统线程低(切换时只需要保存必要的寄存器)
- Goroutine采用的是半抢占式的协作调度(在函数入口处插入协作代码)
- IO/sleep/runtime.Gosched 均会导致调度
- Goroutine故意设计为没有ID
注意:Goroutine是一种资源,也有泄露的风险!
其它内容待续
在线浏览幻灯片:
https://talks.godoc.org/github.com/chai2010/awesome-go-zh/chai2010/chai2010-golang-concurrency.slide
幻灯片源文件:
https://github.com/chai2010/awesome-go-zh/tree/master/chai2010